作者:魏文术 王彦博 姚宏宇 倪光南
作者单位:华夏银行股份有限公司,龙盈智达(北京)科技有限公司,北京友友天宇系统技术有限公司,中国工程院
2021年11月1日,《中华人民共和国个人信息保护法》正式施行,标志着我国的隐私立法时代正式开启。同时,随着数字经济的发展,数据要素重要性的确立与数据基础设施、数据法律法规、数据交易生态不够完善之间的矛盾日益凸显。面对越来越严格的合规与监管,特别是数据安全、信息保护、个人隐私保护等法规和技术标准的逐步健全,原来野蛮生长、明文传输个人隐私数据的大数据服务模式出现断崖式阵痛。
在隐私立法时代,隐私计算相关技术应运而生,该类技术主要关注数据资产的可用性、可见性和可得性,以可见性为例又分为可见、不可见和适度可见。在数据“可用、可见、可得”的情形下,对敏感信息进行自动分类分级的智能识别技术尤为关键。针对数据“可用、不可见、不可得”的情形,视数据用途为信息加工汇总或机器学习建模的不同,可选择采用多方安全计算(Secure Multi-Party Computation,MPC)或联邦学习(Federated Learning,FL)等技术方案;针对数据“可用、适度可见、不可得”的情形,除了普遍采用的可信执行环境(Trusted Execution Environment,TEE)技术方案,数据虚拟化技术(Data Virtualization,DV)也是非常有效的解决方案。
随着数据规模的扩展、数据复杂度的提升和数据多样性的增加,业界对数据资产管理的要求进入了一个全新的高度,传统的数据处理技术面临严峻挑战。对于企业和机构而言,亟须一种可以融合数据、整合资源、消除数据孤岛的技术来满足业务发展需求。数据虚拟化可以在不考虑其物理存储或异构结构的情况下访问数据,通过数据视图及权限控制“按需”提供数据、参与计算,同时,源数据依然留在原处,能够满足在实际应用中对数据“可用、适度可见、不可得”的需要。本文立足于商业银行视角,深入研究数据虚拟化技术及其在商业银行领域的应用,以期助力商业银行在隐私立法时代下的数据资产管理升级。
数据虚拟化一词最早出现于埃里克·布劳顿(Eric Broughton)在2005年发表的论文中。数据虚拟化的历史与数据处理技术密切相关。在数据处理技术的历史中,前后经历了三个主要的发展阶段:1.0阶段,即“计算机时代”,业务发展逐渐形成大量需求各异的数据处理场景,出现了基于不同组织形式的多种“数据库”技术;2.0阶段,即“网络时代”,数据体量及复杂度呈现爆发式增长,传统的数据库技术捉襟见肘,随之发展了数据库集群等大规模分布式处理技术,同时针对不同类型的业务需求,出现了更多专项高效的数据处理技术,如MPP、Hadoop、数据湖等;在当下的3.0阶段,即“数据时代”,随着业务数据体系的极度膨胀,数据变得越来越复杂(多源、异构、跨域),每个应用有效使用所有数据变得越来越困难。如何能够高效可靠地处理多环节、多体系间高动态、强关联海量数据,形成有效的技术解决方案,已成为金融企业成功转型的关键。
数据虚拟化是随着数据处理技术的时代演进而必然出现的一种数据处理技术,是数据处理3.0时代的高阶版本。该技术使金融业务能够实时访问、管理、集成和聚合来自不同来源的数据,既不受其物理位置或格式的影响,也不必关心底层的复杂性,因而受到了金融业机构的广泛关注。
国际数据管理协会(DAMA)数据管理知识体系(DMBOK)对数据虚拟化的定义如下:“数据虚拟化使分布式数据库以及多个异构数据存储可以作为单个数据库进行访问和查看。数据虚拟化服务器不是使用转换引擎对数据执行物理ETL(数据仓库技术),而是虚拟地执行数据提取、转换和集成。”图1展现了数据虚拟化与数据源、业务分析之间的关系。
 数据虚拟化允许在一个视图中集成和聚合来自不同物理位置和不同格式的数据,无需将数据移动到中央存储器中。虽然所有数据都保存在源系统中,但数据虚拟化创建了一个虚拟层,以支持实时访问,并可以对其进行操作和管理,在虚拟视图中转换数据。数据虚拟化的核心是虚拟层,无论数据是在本地还是在云中,它都能使数据或业务用户独立于其格式、源和物理位置来操作、连接和计算数据。虚拟层还允许在不同的虚拟模式和虚拟视图中组织数据,用户可以使用其业务逻辑轻松地丰富源系统中的原始数据,并为分析、报告或自动化流程准备数据。
与传统ETL工具等简单的数据存储复制器不同,数据虚拟化通常不会持久化地来自源系统的数据,只存储元数据以提供虚拟视图,并支持创建单个集成逻辑,从底层源系统实时获取数据,并将集成的数据实时交付到任何前端或应用程序。与传统的数据处理技术相比,数据虚拟化技术具有以下三大优势:一是数据“可用”,数据虚拟化提供了对数据长度和广度的无缝触达,并允许快速原型化,进而给企业和组织带来高效的解决方案,加快和改善决策过程,提高业务敏捷性;二是数据虚拟化隐藏了数据环境的复杂性,使数据工程团队在更短的时间内完成更多工作,且数据源或前端解决方案的变更不会导致昂贵且复杂的重组,因而易于使用,能在降低成本的同时带来更高的扩展性,实现敏捷开发;三是借助新增的数据管控策略及用户和权限管理,数据虚拟化实现了统一且安全的数据治理,保障数据“适度可见”,在数据可用的同时“不可得”。
作为典型的数据密集型行业,银行数据虚拟化技术可有效解决数据所有者与数据使用者之间的鸿沟。
在银行的分布式数据系统中,众多数据库可能采用相同的模式存储,也有可能采用不同的模式存储。对于采用相同的存储模式,可能有多个存储销售数据或交易数据的数据库,每个数据库存储一组租户或一个地区的数据,数据虚拟化技术可以检测各个系统中的数据模式,并使它们在数据虚拟化过程中以单一模式出现,这个过程就称为模式归并。对于不同的存储模式,数据虚拟化技术通过多模式协议解析实现统一的数据访问。例如,通过SQL协议解析引擎,将输入的SQL语句解析成各数据库的方言,由各数据库处理和执行,处理结果返回给虚拟化层,合并后返回给应用。通过模式归并和多模式协议解析,数据虚拟化技术使多源异构数据变得可用,进而有效支撑金融业务场景。
数据虚拟化技术通过适配每个数据源的处理能力,在每个数据源的实际存储位置访问数据,可以避免移动和复制数据所造成的延迟,在对数据实时性要求较高的应用场景如欺诈检测中,这一能力非常关键。此外,所有存储库数据都可实时访问,并执行数据质量校验,基本上消除了监管问题以及数据出错问题,可快速完成风险报告与分析。
针对数据“可见”,数据虚拟化技术支持对不同类型的数据系统进行关联查询,例如通过一条SQL语句对存储在Oracle数据库、MySQL数据库以及Hadoop中的数据进行分析。由于不需要抽取、转换和加载(ETL)以及复制数据存储,所以能够加快处理速度。与迁移数据的方法相比,该流程能够更迅速、更可靠地为决策应用或分析人员提供实时访问能力。此外,数据虚拟化技术还可以与数据迁移的方法进行互补,因为有时候出于历史记录、归档或监管的目的,仍然有必要复制和移动一些数据。
数据虚拟化技术可提供精巧的视图定义工具,支持针对不同类型而且可能分布在不同地理位置的数据库定义全局逻辑数据库和逻辑数据视图,如图2所示。
数据虚拟化技术还可以通过可视化图表的形式展示数据资源总览信息和分类统计信息,如图3所示。
数据虚拟化允许在一个视图中集成和聚合来自不同物理位置和不同格式的数据,无需将数据移动到中央存储器中。虽然所有数据都保存在源系统中,但数据虚拟化创建了一个虚拟层,以支持实时访问,并可以对其进行操作和管理,在虚拟视图中转换数据。数据虚拟化的核心是虚拟层,无论数据是在本地还是在云中,它都能使数据或业务用户独立于其格式、源和物理位置来操作、连接和计算数据。虚拟层还允许在不同的虚拟模式和虚拟视图中组织数据,用户可以使用其业务逻辑轻松地丰富源系统中的原始数据,并为分析、报告或自动化流程准备数据。
与传统ETL工具等简单的数据存储复制器不同,数据虚拟化通常不会持久化地来自源系统的数据,只存储元数据以提供虚拟视图,并支持创建单个集成逻辑,从底层源系统实时获取数据,并将集成的数据实时交付到任何前端或应用程序。与传统的数据处理技术相比,数据虚拟化技术具有以下三大优势:一是数据“可用”,数据虚拟化提供了对数据长度和广度的无缝触达,并允许快速原型化,进而给企业和组织带来高效的解决方案,加快和改善决策过程,提高业务敏捷性;二是数据虚拟化隐藏了数据环境的复杂性,使数据工程团队在更短的时间内完成更多工作,且数据源或前端解决方案的变更不会导致昂贵且复杂的重组,因而易于使用,能在降低成本的同时带来更高的扩展性,实现敏捷开发;三是借助新增的数据管控策略及用户和权限管理,数据虚拟化实现了统一且安全的数据治理,保障数据“适度可见”,在数据可用的同时“不可得”。
作为典型的数据密集型行业,银行数据虚拟化技术可有效解决数据所有者与数据使用者之间的鸿沟。
在银行的分布式数据系统中,众多数据库可能采用相同的模式存储,也有可能采用不同的模式存储。对于采用相同的存储模式,可能有多个存储销售数据或交易数据的数据库,每个数据库存储一组租户或一个地区的数据,数据虚拟化技术可以检测各个系统中的数据模式,并使它们在数据虚拟化过程中以单一模式出现,这个过程就称为模式归并。对于不同的存储模式,数据虚拟化技术通过多模式协议解析实现统一的数据访问。例如,通过SQL协议解析引擎,将输入的SQL语句解析成各数据库的方言,由各数据库处理和执行,处理结果返回给虚拟化层,合并后返回给应用。通过模式归并和多模式协议解析,数据虚拟化技术使多源异构数据变得可用,进而有效支撑金融业务场景。
数据虚拟化技术通过适配每个数据源的处理能力,在每个数据源的实际存储位置访问数据,可以避免移动和复制数据所造成的延迟,在对数据实时性要求较高的应用场景如欺诈检测中,这一能力非常关键。此外,所有存储库数据都可实时访问,并执行数据质量校验,基本上消除了监管问题以及数据出错问题,可快速完成风险报告与分析。
针对数据“可见”,数据虚拟化技术支持对不同类型的数据系统进行关联查询,例如通过一条SQL语句对存储在Oracle数据库、MySQL数据库以及Hadoop中的数据进行分析。由于不需要抽取、转换和加载(ETL)以及复制数据存储,所以能够加快处理速度。与迁移数据的方法相比,该流程能够更迅速、更可靠地为决策应用或分析人员提供实时访问能力。此外,数据虚拟化技术还可以与数据迁移的方法进行互补,因为有时候出于历史记录、归档或监管的目的,仍然有必要复制和移动一些数据。
数据虚拟化技术可提供精巧的视图定义工具,支持针对不同类型而且可能分布在不同地理位置的数据库定义全局逻辑数据库和逻辑数据视图,如图2所示。
数据虚拟化技术还可以通过可视化图表的形式展示数据资源总览信息和分类统计信息,如图3所示。
为了实现数据“适度可见”,数据虚拟化技术在原有数据管控的基础上叠加了一层数据管控策略,保证需要参与跨数据资源协同计算的数据可见,而其他无关数据则不可见,并且不同的计算和不同的数据消费者可见的数据也不同,真正实现了“按需可见、适度可见”。
数据“不可得”——数据不搬家
银行业具有天然的数据禀赋,但数据产权归属也具有天然的复杂性。一方面,产权主体多元,在数据从收集、流转到加工并沉淀为数据资产的过程中,会产生大量衍生数据,而衍生数据资产的主体往往与原始数据主体不一致,造成数据产权边界不清。另一方面,数据资产存在产权交叉的情况。以银行交易数据为例,数据既来源于客户的交易行为,又由银行的信息系统产生,产权交叉增加了数据确权的难度。而在监管和合规越来越严格、个人隐私保护等法规逐步健全的情况下,数据“不敢给”的情况日益加剧,当“数据是重要资产”成为社会共识后,数据“不愿给”也成为司空见惯的现象。
针对这些困境,数据虚拟化技术可将所有数据源连接到一组虚拟的能够实现自我平衡的数据源或数据库中,不需要将数据复制和存储到集中位置再进行分析查询,如图4所示。
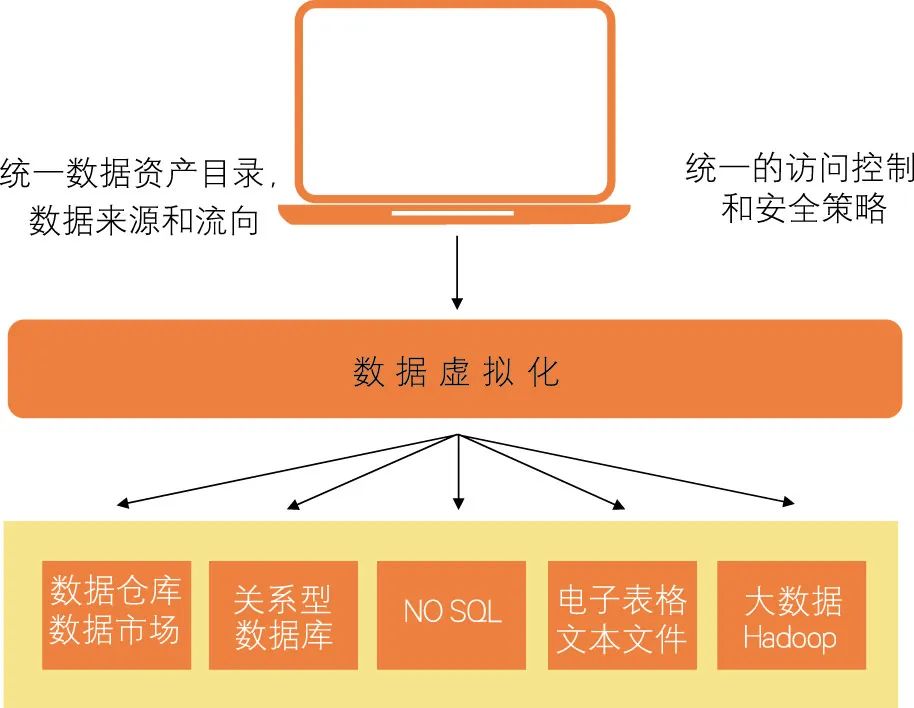
在数据虚拟化技术的支撑下,分析应用提交的查询,在数据源所在的服务器上处理分析工作,查询结果合并到群集中,并返回给原始应用,因此不需要复制任何数据,数据始终保留在数据源中,能在数据“不搬家”的情况下实现数据“可用不可得”,从而有效保障数据所有权与使用权的分割与安全。
扫描二维码,查看案例实践详情!







评论 (0)